免费背景音人声分离解决方案MVSEP-MDX23,足以和Spleeter分庭抗礼

在音视频领域,把已经发布的混音歌曲或者音频文件逆向分离一直是世界性的课题。音波混合的物理特性导致在没有原始工程文件的情况下,将其还原和分离是一件很有难度的事情。
言及背景音人声分离技术,就不能不提Spleeter,它是一种用于音频源分离(音乐分离)的开源深度学习算法,由Deezer研究团队开发。使用的是一个性能取向的音源分离算法,并且为用户提供了已经预训练好的模型,能够开箱即用,这也是Spleeter泛用性高的原因之一,关于Spleeter,请移步:人工智能AI库Spleeter免费人声和背景音乐分离实践(Python3.10),这里不再赘述。
MVSEP-MDX23背景音人声分离技术由Demucs研发,Demucs来自Facebook Research团队,它的发源晚于Spleeter,早于MDX-Net,并且经历过4个大版本的迭代,每一代的模型结构都被大改。Demucs的生成质量从v3开始大幅质变,一度领先行业平均水平,v4是现在最强的开源乐器分离单模型,v1和v2的网络模型被用作MDX-net其中的一部分。
本次我们基于MVSEP-MDX23来对音频的背景音和人声进行分离。
本地分离人声和背景音
如果本地离线运行MVSEP-MDX23,首先克隆代码:
git clone https://github.com/jarredou/MVSEP-MDX23-Colab_v2.git 随后进入项目并安装依赖:
cd MVSEP-MDX23-Colab_v2
pip3 install -r requirements.txt 随后直接进推理即可:
python3 inference.py --input_audio test.wav --output_folder ./results/ 这里将test.wav进行人声分离,分离后的文件在results文件夹生成。
注意推理过程中会将分离模型下载到项目的models目录,极其巨大。
同时推理过程相当缓慢。
这里可以添加--single_onnx参数来提高推理速度,但音质上有一定的损失。
如果本地设备具备12G以上的显存,也可以添加--large_gpu参数来提高推理的速度。
如果本地没有N卡或者显存实在捉襟见肘,也可以通过--cpu参数来使用cpu进行推理,但是并不推荐这样做,因为本来就慢,用cpu就更慢了。
令人暖心的是,官方还利用Pyqt写了一个小的gui界面来提高操作友好度:
__author__ = 'Roman Solovyev (ZFTurbo), IPPM RAS'
if __name__ == '__main__':
import os
gpu_use = "0"
print('GPU use: {}'.format(gpu_use))
os.environ["CUDA_VISIBLE_DEVICES"] = "{}".format(gpu_use)
import time
import os
import numpy as np
from PyQt5.QtCore import *
from PyQt5 import QtCore
from PyQt5.QtWidgets import *
import sys
from inference import predict_with_model
root = dict()
class Worker(QObject):
finished = pyqtSignal()
progress = pyqtSignal(int)
def __init__(self, options):
super().__init__()
self.options = options
def run(self):
global root
# Here we pass the update_progress (uncalled!)
self.options['update_percent_func'] = self.update_progress
predict_with_model(self.options)
root['button_start'].setDisabled(False)
root['button_finish'].setDisabled(True)
root['start_proc'] = False
self.finished.emit()
def update_progress(self, percent):
self.progress.emit(percent)
class Ui_Dialog(object):
def setupUi(self, Dialog):
global root
Dialog.setObjectName("Settings")
Dialog.resize(370, 180)
self.checkbox_cpu = QCheckBox("Use CPU instead of GPU?", Dialog)
self.checkbox_cpu.move(30, 10)
self.checkbox_cpu.resize(320, 40)
if root['cpu']:
self.checkbox_cpu.setChecked(True)
self.checkbox_single_onnx = QCheckBox("Use single ONNX?", Dialog)
self.checkbox_single_onnx.move(30, 40)
self.checkbox_single_onnx.resize(320, 40)
if root['single_onnx']:
self.checkbox_single_onnx.setChecked(True)
self.pushButton_save = QPushButton(Dialog)
self.pushButton_save.setObjectName("pushButton_save")
self.pushButton_save.move(30, 120)
self.pushButton_save.resize(150, 35)
self.pushButton_cancel = QPushButton(Dialog)
self.pushButton_cancel.setObjectName("pushButton_cancel")
self.pushButton_cancel.move(190, 120)
self.pushButton_cancel.resize(150, 35)
self.retranslateUi(Dialog)
QtCore.QMetaObject.connectSlotsByName(Dialog)
self.Dialog = Dialog
# connect the two functions
self.pushButton_save.clicked.connect(self.return_save)
self.pushButton_cancel.clicked.connect(self.return_cancel)
def retranslateUi(self, Dialog):
_translate = QtCore.QCoreApplication.translate
Dialog.setWindowTitle(_translate("Settings", "Settings"))
self.pushButton_cancel.setText(_translate("Settings", "Cancel"))
self.pushButton_save.setText(_translate("Settings", "Save settings"))
def return_save(self):
global root
# print("save")
root['cpu'] = self.checkbox_cpu.isChecked()
root['single_onnx'] = self.checkbox_single_onnx.isChecked()
self.Dialog.close()
def return_cancel(self):
global root
# print("cancel")
self.Dialog.close()
class MyWidget(QWidget):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
self.resize(560, 360)
self.move(300, 300)
self.setWindowTitle('MVSEP music separation model')
self.setAcceptDrops(True)
def dragEnterEvent(self, event):
if event.mimeData().hasUrls():
event.accept()
else:
event.ignore()
def dropEvent(self, event):
global root
files = [u.toLocalFile() for u in event.mimeData().urls()]
txt = ''
root['input_files'] = []
for f in files:
root['input_files'].append(f)
txt += f + '\n'
root['input_files_list_text_area'].insertPlainText(txt)
root['progress_bar'].setValue(0)
def execute_long_task(self):
global root
if len(root['input_files']) == 0 and 1:
QMessageBox.about(root['w'], "Error", "No input files specified!")
return
root['progress_bar'].show()
root['button_start'].setDisabled(True)
root['button_finish'].setDisabled(False)
root['start_proc'] = True
options = {
'input_audio': root['input_files'],
'output_folder': root['output_folder'],
'cpu': root['cpu'],
'single_onnx': root['single_onnx'],
'overlap_large': 0.6,
'overlap_small': 0.5,
}
self.update_progress(0)
self.thread = QThread()
self.worker = Worker(options)
self.worker.moveToThread(self.thread)
self.thread.started.connect(self.worker.run)
self.worker.finished.connect(self.thread.quit)
self.worker.finished.connect(self.worker.deleteLater)
self.thread.finished.connect(self.thread.deleteLater)
self.worker.progress.connect(self.update_progress)
self.thread.start()
def stop_separation(self):
global root
self.thread.terminate()
root['button_start'].setDisabled(False)
root['button_finish'].setDisabled(True)
root['start_proc'] = False
root['progress_bar'].hide()
def update_progress(self, progress):
global root
root['progress_bar'].setValue(progress)
def open_settings(self):
global root
dialog = QDialog()
dialog.ui = Ui_Dialog()
dialog.ui.setupUi(dialog)
dialog.exec_()
def dialog_select_input_files():
global root
files, _ = QFileDialog.getOpenFileNames(
None,
"QFileDialog.getOpenFileNames()",
"",
"All Files (*);;Audio Files (*.wav, *.mp3, *.flac)",
)
if files:
txt = ''
root['input_files'] = []
for f in files:
root['input_files'].append(f)
txt += f + '\n'
root['input_files_list_text_area'].insertPlainText(txt)
root['progress_bar'].setValue(0)
return files
def dialog_select_output_folder():
global root
foldername = QFileDialog.getExistingDirectory(
None,
"Select Directory"
)
root['output_folder'] = foldername + '/'
root['output_folder_line_edit'].setText(root['output_folder'])
return foldername
def create_dialog():
global root
app = QApplication(sys.argv)
w = MyWidget()
root['input_files'] = []
root['output_folder'] = os.path.dirname(os.path.abspath(__file__)) + '/results/'
root['cpu'] = False
root['single_onnx'] = False
button_select_input_files = QPushButton(w)
button_select_input_files.setText("Input audio files")
button_select_input_files.clicked.connect(dialog_select_input_files)
button_select_input_files.setFixedHeight(35)
button_select_input_files.setFixedWidth(150)
button_select_input_files.move(30, 20)
input_files_list_text_area = QTextEdit(w)
input_files_list_text_area.setReadOnly(True)
input_files_list_text_area.setLineWrapMode(QTextEdit.NoWrap)
font = input_files_list_text_area.font()
font.setFamily("Courier")
font.setPointSize(10)
input_files_list_text_area.move(30, 60)
input_files_list_text_area.resize(500, 100)
button_select_output_folder = QPushButton(w)
button_select_output_folder.setText("Output folder")
button_select_output_folder.setFixedHeight(35)
button_select_output_folder.setFixedWidth(150)
button_select_output_folder.clicked.connect(dialog_select_output_folder)
button_select_output_folder.move(30, 180)
output_folder_line_edit = QLineEdit(w)
output_folder_line_edit.setReadOnly(True)
font = output_folder_line_edit.font()
font.setFamily("Courier")
font.setPointSize(10)
output_folder_line_edit.move(30, 220)
output_folder_line_edit.setFixedWidth(500)
output_folder_line_edit.setText(root['output_folder'])
progress_bar = QProgressBar(w)
# progress_bar.move(30, 310)
progress_bar.setValue(0)
progress_bar.setGeometry(30, 310, 500, 35)
progress_bar.setAlignment(QtCore.Qt.AlignCenter)
progress_bar.hide()
root['progress_bar'] = progress_bar
button_start = QPushButton('Start separation', w)
button_start.clicked.connect(w.execute_long_task)
button_start.setFixedHeight(35)
button_start.setFixedWidth(150)
button_start.move(30, 270)
button_finish = QPushButton('Stop separation', w)
button_finish.clicked.connect(w.stop_separation)
button_finish.setFixedHeight(35)
button_finish.setFixedWidth(150)
button_finish.move(200, 270)
button_finish.setDisabled(True)
button_settings = QPushButton('⚙', w)
button_settings.clicked.connect(w.open_settings)
button_settings.setFixedHeight(35)
button_settings.setFixedWidth(35)
button_settings.move(495, 270)
button_settings.setDisabled(False)
mvsep_link = QLabel(w)
mvsep_link.setOpenExternalLinks(True)
font = mvsep_link.font()
font.setFamily("Courier")
font.setPointSize(10)
mvsep_link.move(415, 30)
mvsep_link.setText('Powered by <a href="https://mvsep.com">MVSep.com</a>')
root['w'] = w
root['input_files_list_text_area'] = input_files_list_text_area
root['output_folder_line_edit'] = output_folder_line_edit
root['button_start'] = button_start
root['button_finish'] = button_finish
root['button_settings'] = button_settings
# w.showMaximized()
w.show()
sys.exit(app.exec_())
if __name__ == '__main__':
create_dialog() 效果如下:
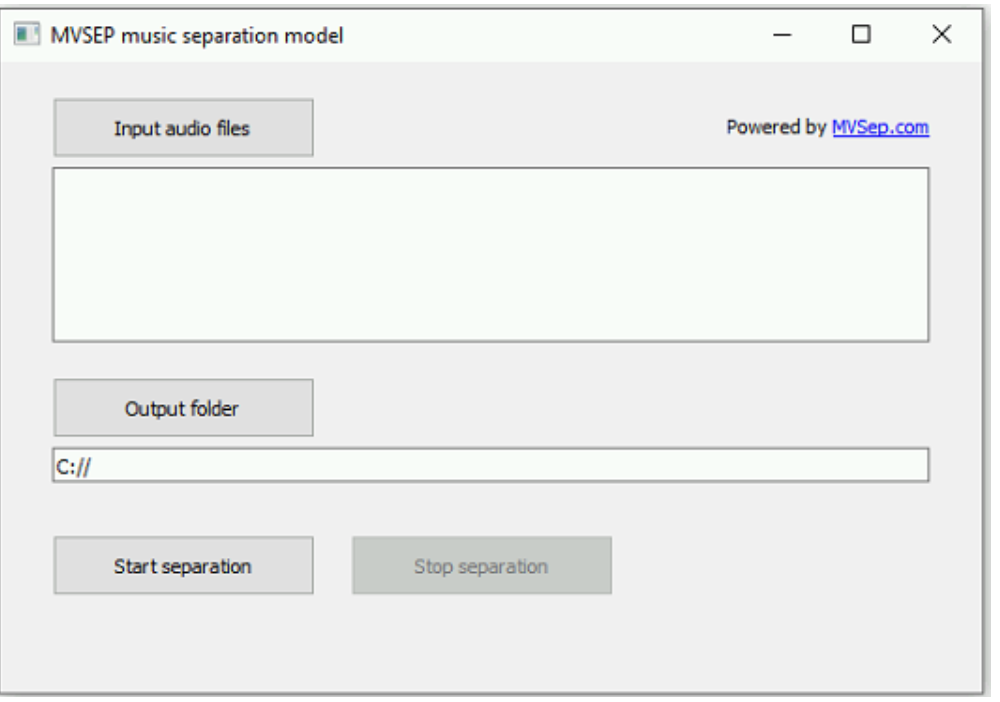
界面虽然朴素,但相当实用,Spleeter可没给我们提供这个待遇。
Colab云端分离人声和背景音
托Google的福,我们也可以在Colab云端使用MVSEP-MDX23:
https://colab.research.google.com/github/jarredou/MVSEP-MDX23-Colab_v2/blob/v2.3/MVSep-MDX23-Colab.ipynb#scrollTo=uWX5WOqjU0QC 首先安装MVSEP-MDX23:
#@markdown #Installation
#@markdown *Run this cell to install MVSep-MDX23*
print('Installing... This will take 1 minute...')
%cd /content
from google.colab import drive
drive.mount('/content/drive')
!git clone https://github.com/jarredou/MVSEP-MDX23-Colab_v2.git &> /dev/null
%cd /content/MVSEP-MDX23-Colab_v2
!pip install -r requirements.txt &> /dev/null
# onnxruntime-gpu nightly fix for cuda12.2
!python -m pip install ort-nightly-gpu --index-url=https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/ort-cuda-12-nightly/pypi/simple/
print('Installation done !') 随后编写推理代码:
#@markdown #Separation
from pathlib import Path
import glob
%cd /content/MVSEP-MDX23-Colab_v2
input = '/content/drive/MyDrive' #@param {type:"string"}
output_folder = '/content/drive/MyDrive/output' #@param {type:"string"}
#@markdown ---
#@markdown *Bigshifts=1 to disable that feature*
BigShifts = 7 #@param {type:"slider", min:1, max:41, step:1}
#@markdown ---
overlap_InstVoc = 1 #@param {type:"slider", min:1, max:40, step:1}
overlap_VitLarge = 1 #@param {type:"slider", min:1, max:40, step:1}
#@markdown ---
weight_InstVoc = 8 #@param {type:"slider", min:0, max:10, step:1}
weight_VitLarge = 5 #@param {type:"slider", min:0, max:10, step:1}
#@markdown ---
use_VOCFT = False #@param {type:"boolean"}
overlap_VOCFT = 0.1 #@param {type:"slider", min:0, max:0.95, step:0.05}
weight_VOCFT = 2 #@param {type:"slider", min:0, max:10, step:1}
#@markdown ---
vocals_instru_only = True #@param {type:"boolean"}
overlap_demucs = 0.6 #@param {type:"slider", min:0, max:0.95, step:0.05}
#@markdown ---
output_format = 'PCM_16' #@param ["PCM_16", "FLOAT"]
if vocals_instru_only:
vocals_only = '--vocals_only true'
else:
vocals_only = ''
if use_VOCFT:
use_VOCFT = '--use_VOCFT true'
else:
use_VOCFT = ''
if Path(input).is_file():
file_path = input
Path(output_folder).mkdir(parents=True, exist_ok=True)
!python inference.py \
--large_gpu \
--weight_InstVoc {weight_InstVoc} \
--weight_VOCFT {weight_VOCFT} \
--weight_VitLarge {weight_VitLarge} \
--input_audio "{file_path}" \
--overlap_demucs {overlap_demucs} \
--overlap_VOCFT {overlap_VOCFT} \
--overlap_InstVoc {overlap_InstVoc} \
--overlap_VitLarge {overlap_VitLarge} \
--output_format {output_format} \
--BigShifts {BigShifts} \
--output_folder "{output_folder}" \
{vocals_only} \
{use_VOCFT}
else:
file_paths = sorted([f'"{glob.escape(path)}"' for path in glob.glob(input + "/*")])[:]
input_audio_args = ' '.join(file_paths)
Path(output_folder).mkdir(parents=True, exist_ok=True)
!python inference.py \
--large_gpu \
--weight_InstVoc {weight_InstVoc} \
--weight_VOCFT {weight_VOCFT} \
--weight_VitLarge {weight_VitLarge} \
--input_audio {input_audio_args} \
--overlap_demucs {overlap_demucs} \
--overlap_VOCFT {overlap_VOCFT} \
--overlap_InstVoc {int(overlap_InstVoc)} \
--overlap_VitLarge {int(overlap_VitLarge)} \
--output_format {output_format} \
--BigShifts {BigShifts} \
--output_folder "{output_folder}" \
{vocals_only} \
{use_VOCFT} 这里默认使用google云盘的目录,也可以修改为当前服务器的目录地址。
结语
MVSEP-MDX23 和 Spleeter 都是音频人声背景音分离软件,作为用户,我们到底应该怎么选择?
MVSEP-MDX23 基于 Demucs4 和 MDX 神经网络架构,可以将音乐分离成“bass”、“drums”、“vocals”和“other”四个部分。MVSEP-MDX23 在 2023 年的音乐分离挑战中获得了第三名,并且在 MultiSong 数据集上的质量比较中表现出色。它提供了 Python 命令行工具和 GUI 界面,支持 CPU 和 GPU 加速,可以在本地运行。
Spleeter 是由 Deezer 开发的开源音频分离库,它使用深度学习模型将音频分离成不同的音轨,如人声、伴奏等。Spleeter 提供了预训练的模型,可以在命令行或作为 Python 库使用。它的优势在于易用性和灵活性,可以根据需要分离不同数量的音轨。
总的来说,MVSEP-MDX23 在音频分离的性能和精度上表现出色,尤其适合需要高质量音频分离的专业用户。而 Spleeter 则更适合普通用户和开发者,因为它易于使用,并且具有更多的定制选项。
- Next Post一键打包,随时运行,Python3项目虚拟环境一键整合包的制作(Venv)
- Previous PostBert-vits2最终版Bert-vits2-2.3云端训练和推理(Colab免费GPU算力平台)